Regression Models and Classification
There are two uses for models, inference and prediction. The former focuses on the information gained from the model in the sense of a variable being a significant influence on the response variable in question and by how much. The latter’s focus is on predicting the value of the response variable given one/some explanatory variables. This one doesn’t care much about ease of interpretation but more on accuracy (the opposite for inference). It really depends on which of these two you are interested in when deciding on the make of your model.
Since I am wanting to predict whether or not one is going to get arrested after committing a crime and getting caught, I am going to use logistic regression. This type of model allows me to use a binary variable as a response variable. I am particularly interested in the the relationship between the the crime and whether or not they get arrested.
The logistic regression equation that I am going to look at is
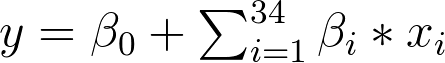
where y is arrested, the x’s are the types of crimes (not including arson, as that gets included in the intercept), and the betas that are not beta-sub-zero are the slopes for the types of crimes.
Because this is a logistic model, you can’t directly interpret the coefficients provided by the model and instead we are going to be looking at odds ratios.
The odds of someone getting arrested for assault are 1.73 times greater than someone getting arrested for arson.
The odds of someone getting arrested for narcotics is 11528 times greater than someone getting arrest for arson.
Something that I personally don’t like about interpreting odds ratios is the fact that you are comparing it to some reference group and if you don’t set what the reference group is then R’s predetermined reference group might not be one you are interested in. So instead, let’s look at a model that has crime type and police districts.
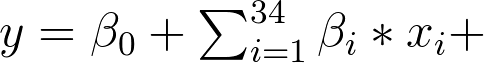
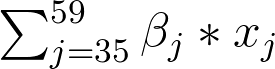
Instead of looking at odds ratios, this time we are going to look at the probability of the person getting arrested based on the crime and the police district that it’s in. For the plot of the probabilities, the crime types we are going to look at: criminal trespass, homicide, public peace violation, and sex offense.
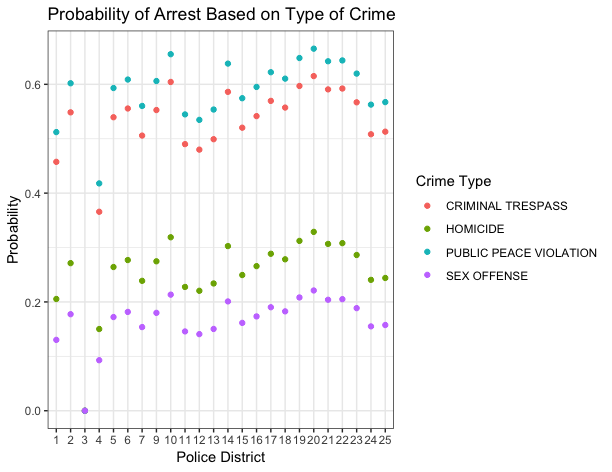
My focus for this project is predicting the whether or not someone will get arrested after getting caught for committing a crime. For this model, we include the police districts to see if certain districts have a higher probability of people getting arrested based on certain crimes. We can see that those committing public peace violation in district 20 have the highest probability of being arrested based on our logistic model. Sex offense in district 3 has the lowest probability of being arrested. Arrest because the person committed a sex offense has the lowest probability across all of the police districts.