Resampling and Tree Based Methods
K-Fold Cross-Validation will randomly divide the observations into k groups/folds of about the same size. This method will rotate through the folds, having one be the validation fold during every iteration. The rest of the folds that are not the validations folds are going to be used to create the model. Then the mean squared error is going to be calculated using the validation fold that was withheld. The main purpose of this is to figure out how good this model is.
We are going to continue to use the same model as the logistic model with 2 explanatory variables, crime type and police district. Whether or not they were arrested is going to be the response variable. We are going to be looking at 10 folds.
Looking at the confusion matrix that was generated, we have that: 205,802 people were correctly predicted to not have been arrested, 23,446 were correctly predicted to have been arrested, 28,827 were incorrectly predicted to not have been arrested, and 4,722 people were incorrectly predicted to have been arrested. The matrix tells us that the model was correct 87.23% of the time. The balanced accuracy is 71.31%, which I am more inclined to look at because the balanced accuracy takes into consideration the class imbalance that is definitely present.

Classification Trees
Since we want to predict whether or not the person gets arrested, we are going to use a classification tree rather than a regression tree. Because there are so many levels within the variables that we are interested in, we are going to collapse them. For the ‘Location.Description’ variable, I have changed it to inside vs outside. For the type of crime, I changed it to violence, violation, sexual, theft, narcotics, and gambling. For this tree we are going to have the response variable still be whether or not they got arrested and the explanatory variables be location of the crime, type of crime and whether or not it’s considered domestic.
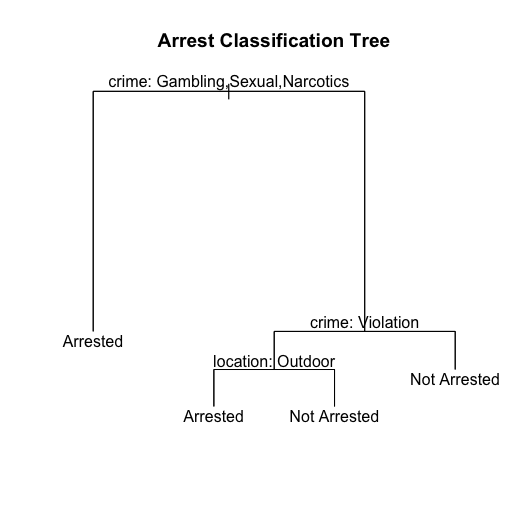
We are seeing that the tree only actually uses type of crime and location of the crime in the construction of the tree and decides not to use whether it’s considered domestic.
If my understanding of classification trees is correct, then the most influential levels of type of crime are up on top, which in this case are gambling, narcotics, and sexual crimes. From there, influence on whether the person gets arrested trickles down as we go further down the tree.